
![]()




このチュートリアルは、FIWARE Cosmos Orion Spark Connector の概要です。これにより、 最も人気のある BigData プラットフォームの1つである Apache Spark と統合され、 コンテキスト全体でビッグデータ分析が容易になります。Apache Spark は、制限のないデータ・ストリームと制限のあるデータ・ ストリームでステートフルな計算を行うためのフレームワークおよび分散処理エンジンです。Spark は、すべての一般的な クラスタ環境で実行され、メモリ内の速度と任意のスケールで計算を実行するように設計されています。
チュートリアルでは全体で cUrl コマンドを使用しますが、Postman のドキュメントとしても利用できます:

リアルタイム処理とビッグデータ分析¶
"You have to find what sparks a light in you so that you in your own way can illuminate the world."
— Oprah Winfrey
FIWARE に基づくスマート・ソリューションは、マイクロサービスを中心に設計されています。したがって、シンプルな アプリケーション (スーパーマーケット・チュートリアルなど) から、IoT センサやその他のコンテキスト・データ・プロバイダの 大規模な配列に基づく都市全体のインストールにスケールアップするように設計されています。
関与する膨大な量のデータは、1台のマシンで分析、処理、保存するには膨大な量になるため、追加の分散サービスに作業を委任する 必要があります。これらの分散システムは、いわゆる ビッグデータ分析 の基礎を形成します。タスクの分散により、開発者は、 従来の方法では処理するには複雑すぎる巨大なデータ・セットから洞察を抽出することができます。隠れたパターンと相関関係を 明らかにします。
これまで見てきたように、コンテキスト・データはすべてのスマート・ソリューションの中核であり、Context Broker は状態の変化を 監視し、コンテキストの変化に応じて、サブスクリプション・イベント を発生させることができます。小規模なインストールの場合、各サブスクリプション・イベントは単一の受信エンドポイントで1つずつ 処理できますが、システムが大きくなると、リスナーを圧倒し、潜在的にリソースをブロックし、更新が失われないようにするために 別の手法が必要になります。
Apache Spark は、オープンソースの分散型汎用クラスタ・コンピューティング・フレームワークです。 暗黙的なデータ並列性と フォールト・トレランスを備えたクラスタ全体をプログラミングするためのインターフェイスを提供します。 Cosmos Spark コネクタを使用すると、開発者はカスタム・ビジネス・ロジックを記述して、コンテキスト・データのサブスクリプション・イベント をリッスンし、コンテキスト・データのフローを処理できます。Spark は、これらのアクションを他のワーカーに委任して、 必要に応じて順次または並行してアクションを実行することができます。 データ・フロー処理自体は、任意に複雑になる可能性が あります。
実際には、明らかに、既存のスーパーマーケットのシナリオは小さすぎて、ビッグデータ・ソリューションの使用を必要としません。 しかし、コンテキスト・データ・イベントの連続ストリームを処理する大規模なソリューションで必要になる可能性のある リアルタイム処理のタイプを示すための基礎として機能します。
アーキテクチャ¶
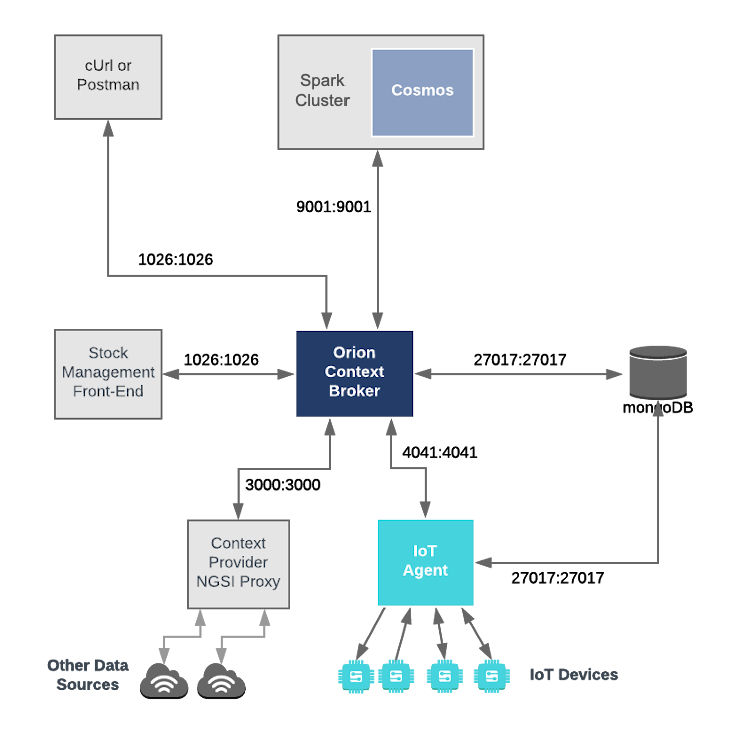
このアプリケーションは、以前のチュートリアルで作成されたコンポーネントと ダミー IoT デバイス上に構築されます。 3つの FIWARE コンポーネントを使用します。 Orion Context Broker, IoT Agent for Ultralight 2.0 および Orion を Apache Spark cluster に接続するための Cosmos Orion Spark Connector です。Spark クラスタ自体は、 実行を調整する単一の Cluster Manager master と、タスクを実行する単一の Worker Nodes worker で構成されます。
Orion Context Broker と IoT Agent はどちらも、オープンソースの MongoDB テクノロジーに依存して、 保持している情報の永続性を維持しています。また、以前のチュートリアルで 作成したダミー IoT デバイスを使用します。
したがって、全体的なアーキテクチャは次の要素で構成されます :
- 独立したマイクロサービスとしての2つの FIWARE Generic Enablers :
- FIWARE Orion Context Brokerは、 NGSI-v2 を使用してリクエストを受信します
- FIWARE IoT Agent for Ultralight 2.0 は、ダミー IoT デバイスから Ultralight 2.0 形式のノースバウンド測定値を受信し、Context Broker の NGSI-v2 リクエストに変換して、コンテキスト・ エンティティの状態を変更します
- Apache Spark cluster は、
単一の ClusterManager と Worker Nodes で構成されます
- FIWARE Cosmos Orion Spark Connector は、 コンテキストの変更をサブスクライブし、リアルタイムで操作を行うデータフローの一部としてデプロイされます
- 1つの MongoDB データベース :
- Orion Context Broker がデータ・エンティティ、サブスクリプション、レジストレーションなどの コンテキスト・データ情報を保持するために使用します
- IoT Agent がデバイスの URL やキーなどのデバイス情報を保持するために使用します
- 3つのコンテキスト・プロバイダ :
- HTTP 上で実行される Ultralight 2.0 を使用する、ダミー IoT デバイス のセットとして 機能する Webサーバ
- 在庫管理フロントエンド は、このチュートリアルでは使用しません。次のことを行います :
- ストア情報を表示し、ユーザがダミー IoT デバイスと対話できるようにします
- 各ストアで購入できる製品を表示します
- ユーザが製品を "購入" して在庫数を減らすことを許可します
- Context Provider NGSI プロキシは、このチュートリアルでは使用しません。次のことを行います :
全体のアーキテクチャを以下に示します :
Spark Cluster の構成¶
spark-master:
image: bde2020/spark-master:2.4.5-hadoop2.7
container_name: spark-master
expose:
- "8080"
- "9001"
ports:
- "8080:8080"
- "7077:7077"
- "9001:9001"
environment:
- INIT_DAEMON_STEP=setup_spark
- "constraint:node==spark-master"spark-worker-1:
image: bde2020/spark-worker:2.4.5-hadoop2.7
container_name: spark-worker-1
depends_on:
- spark-master
ports:
- "8081:8081"
environment:
- "SPARK_MASTER=spark://spark-master:7077"
- "constraint:node==spark-master"spark-master コンテナは、3つのポートでリッスンしています:
- ポート
8080は、Apache Spark-Master ダッシュボードの Web フロントエンドを見ることができる ように、公開されます - ポート
7070は内部通信に使用されます - ポート
9001は、インストレーションがコンテキスト・データのサブスクリプションを受信できるように、 公開されます
spark-worker-1 コンテナは、1つのポートで待機しています:
- ポート
8081は、Apache Spark-Worker-1 ダッシュボードの Web フロントエンドを見ることができる ように、公開されます
前提条件¶
Docker および Docker Compose¶
物事を単純にするために、すべてのコンポーネントは Docker を使用して実行されます。 Docker は、さまざまなコンポーネントをそれぞれの環境に分離できるようにするコンテナ・テクノロジーです。
- Windows に Docker をインストールするには、こちらの指示に従って ください
- Mac に Docker をインストールするには、こちらの指示に従ってください
- Linux に Docker をインストールするには、こちらの指示に従ってください
Docker Compose は、マルチ・コンテナ Docker アプリケーションを定義および実行するためのツールです。一連の YAML files は、アプリケーション に必要なサービスを構成するために使用されます。これは、すべてのコンテナ・サービスを単一のコマンドで起動できることを 意味します。Docker Compose は、デフォルトで Docker for Windows および Docker for Mac の一部としてインストール されますが、Linux ユーザはこちらにある指示に従う必要があります。
次のコマンドを使用して、現在の Docker および Docker Compose バージョンを確認できます :
docker-compose -v
docker versionDocker バージョン20.10 以降および Docker Compose 1.29 以降を使用していることを確認し、必要に応じてアップグレード してください。
Maven¶
Apache Maven は、ソフトウェア・プロジェクト管理ツールです。プロジェクト・ オブジェクト・モデル (POM) の概念に基づいて、Maven は情報の中心部分からプロジェクトのビルド、レポート、および ドキュメントを管理できます。Maven を使用して、依存関係を定義およびダウンロードし、コードをビルドして JAR ファイルに パッケージ化します。
Cygwin for Windows¶
簡単な Bash スクリプトを使用してサービスを開始します。Windows ユーザは、cygwin を ダウンロードして、Windows 上の Linux ディストリビューションに類似したコマンドライン機能を提供する必要があります。
起動¶
開始する前に、必要な Docker イメージをローカルで取得または構築したことを確認する必要があります。以下に示すコマンド を実行して、リポジトリを複製し、必要なイメージを作成してください。いくつかのコマンドを特権ユーザとして実行する 必要がある場合があることに注意してください :
git clone https://github.com/FIWARE/tutorials.Big-Data-Spark.git
cd tutorials.Big-Data-Spark
checkout NGSI-v2
./services createこのコマンドは、以前のチュートリアルからシードデータをインポートし、起動時にダミー IoT センサをプロビジョニング します。
システムを起動するには、次のコマンドを実行します:
./services start注 : クリーンアップしてやり直す場合は、次のコマンドを使用します :
./services stop
リアルタイム処理操作¶
Apache Spark のドキュメント によると、Spark Streaming はコア Spark API の拡張であり、ライブ・データ・ストリームのスケーラブルで高スループットのフォールト・トレラントなストリーム処理を 可能にします。データは、Kafka, Flume, Kinesis, TCP ソケットなどの多くのソースから取り込むことができ、map, reduce, join, window などの高レベル関数で表現された複雑なアルゴリズムを使用して処理できます。最後に、処理されたデータを ファイルシステム、データベース、およびライブ・ダッシュボードにプッシュできます。 実際、Spark の機械学習とグラフ処理アルゴリズムをデータ・ストリームに適用できます。

内部的には、次のように動作します。Spark Streaming は、ライブ入力データ・ストリームを受信し、データをバッチに分割します。 バッチは、Spark エンジンによって処理され、結果の最終ストリームがバッチで生成されます。

これは、ストリーミング・データフローを作成するには、以下を提供する必要があることを意味します:
- Source Operator としてコンテキスト・データを読み取るためのメカニズム
- 変換操作 (transform operations) を定義するビジネスロジック
- Sink Operator としてコンテキスト・データを Context Broker にプッシュバックするメカニズム
Cosmos Spark connector - orion.spark.connector-1.2.2.jar は、Source および Sink operators の両方を
提供します。したがって、ストリーミング・データフロー・パイプライン操作を相互に接続するために必要な Scala コードを
記述するだけです。処理コードは、Spark クラスタにアップロードできる JAR ファイルにコンパイルできます。
以下に2つの例を詳しく説明します。このチュートリアルのすべてのソースコードは、
cosmos-examples
ディレクトリにあります。
その他の Spark 処理の例は、 Spark Connector の例 にあります。
Spark 用の JAR ファイルのコンパイル¶
サンプル JAR ファイルをビルドするために必要な前提条件を保持する既存の pom.xml ファイルが作成されました。
Orion Spark Connector を使用するには、最初に Maven を使用してアーティファクトとしてコネクタ JAR を手動でインストールする必要があります:
cd cosmos-examples
curl -LO https://github.com/ging/fiware-cosmos-orion-spark-connector/releases/download/FIWARE_7.9.1/orion.spark.connector-1.2.2.jar
mvn install:install-file \
-Dfile=./orion.spark.connector-1.2.2.jar \
-DgroupId=org.fiware.cosmos \
-DartifactId=orion.spark.connector \
-Dversion=1.2.2 \
-Dpackaging=jarその後、同じディレクトリ (cosmos-examples) 内で mvn package コマンドを実行することにより、
ソースコードをコンパイルできます:
mvn packagecosmos-examples-1.2.2.jar と呼ばれる新しい JAR ファイルが cosmos-examples/target ディレクトリ内に作成されます。
コンテキスト・データのストリームの生成¶
このチュートリアルでは、コンテキストが定期的に更新されているシステムを監視する必要があります。 ダミー IoT センサを
使用してこれを行うことができます。http://localhost:3000/device/monitor でデバイス・モニタ。ページを開き、
Smart Door のロックを解除して、Smart Lamp をオンにします。これは、ドロップ・ダウン。リストから適切なコマンドを
選択し、send ボタンを押すことで実行できます。デバイスからの測定の流れは、同じページで見ることができます:

ロガー - コンテキスト・データのストリームの読み取り¶
最初の例では、Orion Context Broker からノーティフィケーションを受信するために OrionReceiver operator を使用します。
具体的には、この例では、各タイプのデバイスが1分間に送信するノーティフィケーションの数をカウントします。
この例のソースコードは、
org/fiware/cosmos/tutorial/Logger.scala
にあります。
ロガー - JAR のインストール¶
必要に応じてコンテナを再起動し、ワーカー・コンテナにアクセスします:
docker exec -it spark-worker-1 bin/bashそして、次のコマンドを実行して、生成された JAR パッケージを Spark クラスタで実行します:
/spark/bin/spark-submit \
--class org.fiware.cosmos.tutorial.Logger \
--master spark://spark-master:7077 \
--deploy-mode client /home/cosmos-examples/target/cosmos-examples-1.2.2.jar \
--conf "spark.driver.extraJavaOptions=-Dlog4jspark.root.logger=WARN,console"ロガー - コンテキスト変更のサブスクライブ¶
動的コンテキスト・システムが稼働し始めたら (Spark クラスタに Logger ジョブをデプロイしました)、コンテキストの変更を
Spark にノーティフィケーションする必要があります。
これは、Orion Context Broker の /v2/subscription エンドポイントに POST リクエストを行うことによって行われます。
-
fiware-serviceおよびfiware-servicepathヘッダは、これらの設定を使用してプロビジョニングされているため、 接続された IoT センサからの測定値のみをリッスンするようにサブスクリプションをフィルタリングするために使用されます -
ノーティフィケーション url は、Spark プログラムがリッスンしているものと一致する必要があります
-
この
throttling値は、変更がサンプリングされるレートを定義します
別のターミナルを開き、次のコマンドを実行します:
1 リクエスト:¶
curl -iX POST \
'http://localhost:1026/v2/subscriptions' \
-H 'Content-Type: application/json' \
-H 'fiware-service: openiot' \
-H 'fiware-servicepath: /' \
-d '{
"description": "Notify Spark of all context changes",
"subject": {
"entities": [
{
"idPattern": ".*"
}
]
},
"notification": {
"http": {
"url": "http://spark-worker-1:9001"
}
}
}'レスポンスは、201 - Created です。
サブスクリプションが作成されている場合は、/v2/subscriptions エンドポイントに対して GET リクエストを行うことで、
サブスクリプションが起動しているかどうかを確認できます。
2 リクエスト:¶
curl -X GET \
'http://localhost:1026/v2/subscriptions/' \
-H 'fiware-service: openiot' \
-H 'fiware-servicepath: /'レスポンス:¶
[
{
"id": "5d76059d14eda92b0686f255",
"description": "Notify Spark of all context changes",
"status": "active",
"subject": {
"entities": [
{
"idPattern": ".*"
}
],
"condition": {
"attrs": []
}
},
"notification": {
"timesSent": 362,
"lastNotification": "2019-09-09T09:36:33.00Z",
"attrs": [],
"attrsFormat": "normalized",
"http": {
"url": "http://spark-worker-1:9001"
},
"lastSuccess": "2019-09-09T09:36:33.00Z",
"lastSuccessCode": 200
}
}
]レスポンスの notification セクション内に、サブスクリプションの状態を説明するいくつかの追加 attributes が表示されます。
サブスクリプションの基準が満たされている場合は、timesSent は、0 より大きい必要があります。ゼロの場合は、
サブスクリプションの subject が正しくないか、サブスクリプションが間違った fiware-service-path または fiware-service
ヘッダで作成されたことを示します。
lastNotification は、最近のタイムスタンプでなければなりません。そうでない場合は、デバイスが定期的にデータを
送信していません。Smart Door のロックを解除し、Smart Lamp をオンにすることを忘れないでください。
lastSuccess は、lastNotification date に一致している必要があります。そうでない場合は、Cosmos は、
適切にサブスクリプションを受信していません。ホスト名とポートが正しいことを確認してください。
最後に、サブスクリプションの status が active であるかどうかを確認します。期限切れのサブスクリプションは起動しません。
ロガー - 出力の確認¶
サブスクリプションを1分間実行したままにします。次に、Spark ジョブを実行したコンソールでの出力は次のようになります:
Sensor(Bell,3)
Sensor(Door,4)
Sensor(Lamp,7)
Sensor(Motion,6)ロガー - コードの分析¶
package org.fiware.cosmos.tutorial
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.fiware.cosmos.orion.spark.connector.OrionReceiver
object Logger{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Logger")
val ssc = new StreamingContext(conf, Seconds(60))
// Create Orion Receiver. Receive notifications on port 9001
val eventStream = ssc.receiverStream(new OrionReceiver(9001))
// Process event stream
val processedDataStream= eventStream
.flatMap(event => event.entities)
.map(ent => {
new Sensor(ent.`type`)
})
.countByValue()
.window(Seconds(60))
processedDataStream.print()
ssc.start()
ssc.awaitTermination()
}
case class Sensor(device: String)
}プログラムの最初の行は、コネクタを含む必要な依存関係をインポートすることを目的としています。次のステップは、
コネクタによって提供されるクラスを使用して OrionReceiver のインスタンスを作成し、それを Spark
によって提供される環境に追加することです。
OrionReceiver コンストラクタは、パラメータとしてポート番号 (9001) を受け入れます。このポートは、Orion から来る
サブスクリプションのノーティフィケーションをリッスンするために使用され、NgsiEvent オブジェクトの DataStream
に変換されます。これらのオブジェクトの定義は、
Orion-Spark Connector ドキュメント
に記載されています。
ストリーム処理は、5つの別々のステップで構成されています。最初のステップ (flatMap()) は、一定期間に受信したすべての
NGSI イベントのエンティティ・オブジェクトをまとめるために実行されます。その後、コードは (map() 操作を使用して)
それらを反復処理し、目的の属性を抽出します。この場合、我々は、センサ type (Door, Motion, Bell または Lamp)
に興味があります。
各反復内で、必要なプロパティであるセンサ type を使用してカスタム・オブジェクトを作成します。この目的のために、
次のようにケース class を定義できます:
case class Sensor(device: String)その後、作成されたオブジェクトをデバイスのタイプ (countByValue()) でカウントし、それらに対して window()
などの操作を実行できます。
処理後、結果はコンソールに出力されます:
processedDataStream.print()Logger - NGSI-LD:¶
同じ例が NGSI-LD 形式 (LoggerLD.scala) のデータに提供されています。この例では、NGSI-LD 形式でメッセージを
受信するために、Orion Spark Connector によって提供される NGSILDReceiver を利用します。変更されるコードの唯一の部分は、
レシーバー (receiver) の宣言です:
...
import org.fiware.cosmos.orion.spark.connector.NGSILDReceiver
...
val eventStream = env.addSource(new NGSILDReceiver(9001))
...このジョブを実行するには、spark-submit コマンドを再度使用して、次のLogger の代わりに LoggerLD
クラスを指定する必要があります:
/spark/bin/spark-submit \
--class org.fiware.cosmos.tutorial.LoggerLD \
--master spark://spark-master:7077 \
--deploy-mode client /home/cosmos-examples/target/cosmos-examples-1.2.2.jar \
--conf "spark.driver.extraJavaOptions=-Dlog4jspark.root.logger=WARN,console"フィードバック・ループ - コンテキスト・データの永続化¶
2番目の例では、Motion Sensorが動きを検出するとSmart Lamp をオンにします。
データフロー・ストリームは、ノーティフィケーションを受信するために OrionReceiver operator を使用し、入力を
フィルタリングして Motion Sensor にのみレスポンスするように入力をフィルタ処理し、次に OrionSink
を使用して処理されたコンテキストを Context Broker にプッシュバックします。この例のソースコードは
org/fiware/cosmos/tutorial/Feedback.scala
にあります。
フィードバック・ループ - JAR のインストール¶
/spark/bin/spark-submit \
--class org.fiware.cosmos.tutorial.Feedback \
--master spark://spark-master:7077 \
--deploy-mode client /home/cosmos-examples/target/cosmos-examples-1.2.2.jar \
--conf "spark.driver.extraJavaOptions=-Dlog4jspark.root.logger=WARN,console"フィードバック・ループ - コンテキスト変更のサブスクライブ¶
前の例が実行されていない場合は、新しいサブスクリプションを設定する必要があります。Motion Sensor が動きを検出したときにのみノーティフィケーションをトリガーするように、より狭いサブスクリプションを設定できます。
注: 前のサブスクリプションがすでに存在する場合、2番目のより狭いモーションのみのサブスクリプションを作成する、 このステップは不要です。Scala タスク自体のビジネス・ロジック内にフィルタがあります。
curl -iX POST \
'http://localhost:1026/v2/subscriptions' \
-H 'Content-Type: application/json' \
-H 'fiware-service: openiot' \
-H 'fiware-servicepath: /' \
-d '{
"description": "Notify Spark of all context changes",
"subject": {
"entities": [
{
"idPattern": "Motion.*"
}
]
},
"notification": {
"http": {
"url": "http://spark-worker-1:9001"
}
}
}'フィードバック・ループ - 出力の確認¶
http://localhost:3000/device/monitor に移動します。
ストア内で、Smart Door のロックを解除して待ちます。Smart Door が開いて Motion Sensor がトリガーされると、 Smart Lamp が直接オンになります。
フィードバック・ループ - コードの分析¶
package org.fiware.cosmos.tutorial
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.fiware.cosmos.orion.spark.connector._
object Feedback {
final val CONTENT_TYPE = ContentType.JSON
final val METHOD = HTTPMethod.PATCH
final val CONTENT = "{\n \"on\": {\n \"type\" : \"command\",\n \"value\" : \"\"\n }\n}"
final val HEADERS = Map("fiware-service" -> "openiot","fiware-servicepath" -> "/","Accept" -> "*/*")
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Feedback")
val ssc = new StreamingContext(conf, Seconds(10))
// Create Orion Receiver. Receive notifications on port 9001
val eventStream = ssc.receiverStream(new OrionReceiver(9001))
// Process event stream
val processedDataStream = eventStream
.flatMap(event => event.entities)
.filter(entity=>(entity.attrs("count").value == "1"))
.map(entity=> new Sensor(entity.id))
.window(Seconds(10))
val sinkStream= processedDataStream.map(sensor => {
val url="http://localhost:1026/v2/entities/Lamp:"+sensor.id.takeRight(3)+"/attrs"
OrionSinkObject(CONTENT,url,CONTENT_TYPE,METHOD,HEADERS)
})
// Add Orion Sink
OrionSink.addSink( sinkStream )
// print the results with a single thread, rather than in parallel
processedDataStream.print()
ssc.start()
ssc.awaitTermination()
}
case class Sensor(id: String)
}ご覧のとおり、前の例と似ています。主な違いは、処理されたデータを OrionSink を介して Context Broker
に書き戻すことです。
OrionSinkObject の引数は次のとおりです:
- Message:
"{\n \"on\": {\n \"type\" : \"command\",\n \"value\" : \"\"\n }\n}". 'on' コマンドを送信します - URL:
"http://localhost:1026/v2/entities/Lamp:"+node.id.takeRight(3)+"/attrs". TakeRight(3) は、Room の番号を取得します (例: '001') - Content Type:
ContentType.Plain. - HTTP Method:
HTTPMethod.POST. - Headers:
Map("fiware-service" -> "openiot","fiware-servicepath" -> "/","Accept" -> "*/*"). オプション・パラメータ。HTTP リクエストに必要なヘッダを追加します。
他のチュートリアルを読むことで見つけることができます
License¶
MIT © 2020-2022 FIWARE Foundation e.V.